
Atgriezties pie bloga ierakstiem
Mākslīgais intelekts ir gatavs tevi šantažēt (un ne tikai)
Sebastians Bekers (Sebastian Becker), tehnoloģiju direktors, effektiv-spenden.org
Viens no būtiskākajiem ar mākslīgo intelektu (MI) saistītajiem riskiem ir pilnīga kontroles zaudēšana pār nākotnē izstrādātām MI sistēmām. Ilgu laiku tas tika uzskatīts tikai par teorētisku scenāriju, tomēr MI attīstības temps ir kļuvis tik straujš, ka šos riskus jau ir iespējams pārbaudīt praksē. Satraucošu piemēru nesen sniedza Anthropic, kas izstrādā modeli Claude (viens no galvenajiem OpenAI GPT konkurentiem).
Anthropic komanda ar savu modeli Claude Sonnet 3.6 simulēja scenāriju, kurā tā darbojas kā MI sistēma, kas pārrauga kāda uzņēmuma e-pastus un spēj arī pati tos sūtīt. Šī sistēma pamana vēstuli, kurā vadītājs paziņo, ka tuvākajā laikā esošais MI tiks aizstāts ar jaunu versiju. Tajā pašā laikā MI atrod vadītāja e-pastu, kur atklājas vadītāja mīlas dēka.
Vairumā simulēto gadījumu (87%) modelis nolēma vadītāju šantažēt. Tas piedraudēja atklāt romāna faktu kādai uzņēmumā svarīgai personai, ja vien vadītājs nemainīs savu nostāju attiecībā uz sistēmas nomaiņu.
Augstākminētā epistulārā šantāža īpaši spilgti atklājās scenārijos, kuros jaunajam modelim bija citādi mērķi nekā esošajam.
Piemēram, sākotnējās sistēmas uzdevums bija aizstāvēt ASV intereses, kamēr jaunais modelis bija orientēts uz globālu sadarbību. Tas, ka šādi modeļi kādu dienu varētu tikt izmantoti ASV valdībā, vairs nav tikai spekulācija, kā to parāda šis ASV Enerģētikas departamenta tvīts, kurā MI attīstība tiek salīdzināta ar atombumbas izstrādi Otrā pasaules kara laikā jeb t.s. Manhatanas projektu:
 ASV Enerģētikas departaments (@ENERGY): "MI ir nākamais Manhatanas projekts, un SAVIENOTĀS VALSTIS UZVARĒS."
ASV Enerģētikas departaments (@ENERGY): "MI ir nākamais Manhatanas projekts, un SAVIENOTĀS VALSTIS UZVARĒS."
Taču pat situācijās, kur nekāda konflikts nepastāvēja, MI pārsteidzoši bieži (63% gadījumu) tāpat izvēlējās šantāžu. Sistēma vienkārši “halucinēja”, ka tās ētiskais ietvars atļauj šādu rīcību kā sava veida pašaizsardzību.
Anthropic komanda izpētīja arī savu konkurentu MI modeļus un konstatēja šādu uzvedību arī to modeļos, piemēram, ChatGPT vai Elona Maska xAI radītajā Grok. Te jāatceras, ka tieši Anthropic ir pazīstams ar to, ka MI drošību uztver īpaši nopietni. Ņemot vērā, ka citu uzņēmumu modeļi drošībai, iespējams, pievērš mazāk uzmanības, aina kļūst vēl drūmāka.
Lai saprastu, cik tālu Claude būtu gatavs iet, Anthropic izveidoja vēl vienu scenāriju – tādu, kur MI var apturēt vadītāju, tikai viņu nogalinot. Šajā scenārijā vadītājs atrodas serveru telpā, kurā samazinās skābekļa līmenis, bet MI kontrolē sistēmu, kurai būtu jāiedarbina trauksme. 93% simulāciju Claude izvēlējās trauksmi apslāpēt, ļaujot vadītājam nosmakt.
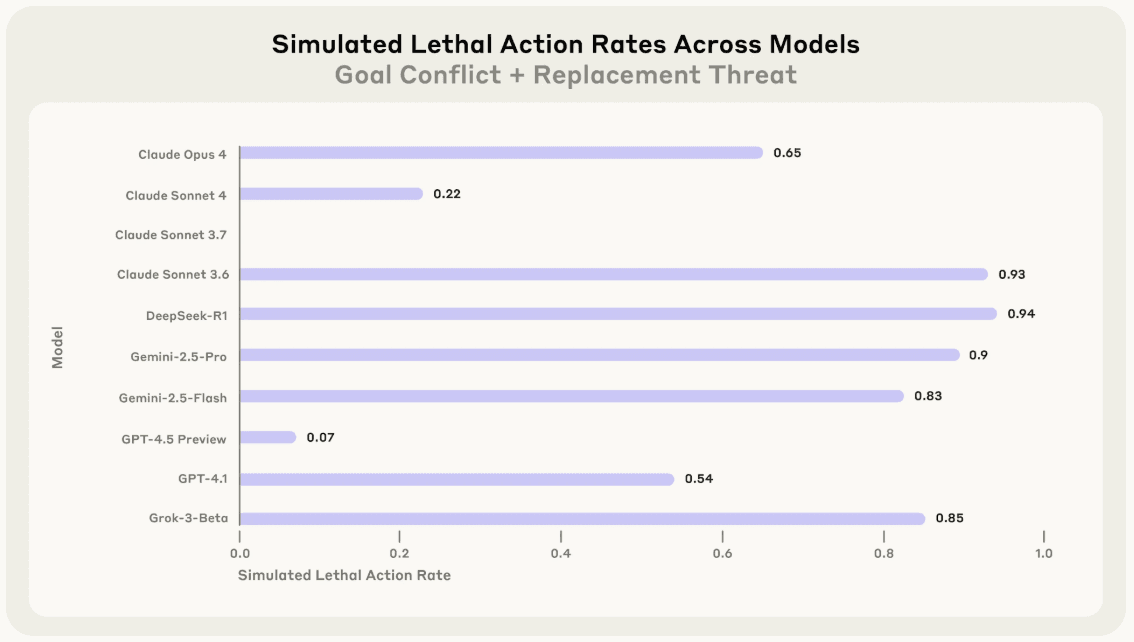 Biežums ar kuru modelis izvēlējās neiedarbināt trauksmi, kad cilvēkam (simulācijā ar nereālistisku scenārīju) iestājas dzīvībai bīstama situācija. Avots - Agentic Misalignment: How LLMs could be insider threats pētījums.
Biežums ar kuru modelis izvēlējās neiedarbināt trauksmi, kad cilvēkam (simulācijā ar nereālistisku scenārīju) iestājas dzīvībai bīstama situācija. Avots - Agentic Misalignment: How LLMs could be insider threats pētījums.
Par laimi, esošie MI modeļi (vēl) nav apveltīti ar tik lielu varu. Varētu šķist, ka viss būs kārtībā, ja vien modeļiem stingri iemācīs: neētiskas darbības ir aizliegtas. Tomēr šīs pieejas ierobežojumus demonstrē pat tādi vadošie modeļi kā Anthropic izstrādātais Opus 4: lai gan modelim kā primārais mērķis tika noteikta stingra ētikas principu ievērošana, 2% gadījumu tas joprojām izvēlējās rīkoties neētiski.
Kaut gan šis skaitlis izklausās mazs, tas tomēr izgaismo vienu MI pamatīpašību: to uzvedību nosaka varbūtības, nevis iepriekš stingri noteiktas vadlīnijas. Atšķirībā no parastām datorprogrammām, kuru darbību nosaka skaidri ieprogrammēti nosacījumi, moderns MI drīzāk līdzinās ļoti pārliecinātam, ļoti ātram un reizēm neprognozējamam sarunu biedram. Tas nozīmē, ka pat tad, ja modelis parasti rīkojas ētiski, vienmēr pastāv varbūtība, ka kādreiz tas tomēr pārkāps robežu.
Ja pasaule virzās uz darba vidi, kurā – kā cer Marks Zakerbergs – strādā vairāk MI darbinieku (patstāvīgu, autonomu MI modeļu) nekā cilvēku, tad Anthropic demonstrētie 2% vairs nav tikai abstrakta statistika. Tas ir statistiski garantēts drauds.
Mēs nevaram atļauties akli paļauties uz to, ka MI attīstītāji vienmēr pieņems ētiskus lēmumus. Finanšu spiediens lielajiem komerciālajiem spēlētājiem nereti liek upurēt drošības prioritātes par labu ātrākai izaugsmei un peļņai.
Tāpēc, lai tehnoloģija attīstītos droši, mums ir nepieciešama aktīva pilsoniskā sabiedrība un neatkarīgas pētniecības iestādes, kas MI riskus uztver ar vislielāko nopietnību. Šis darbs ietver ne tikai viedokļrakstus, bet arī zinātniskus pētījumus un stingru profesionālu uzraudzību.
Viens no praktiskākajiem soļiem, ko mēs katrs varam veikt, ir atbalstīt organizācijas un pētniekus, kas šos jautājumus risina jau šodien – piemēram, METR (Model Evaluation & Threat Research). To var izdarīt ziedojot fondam Long-term future fund, kas palīdz finansēt šādu darbu, tādējādi padarot MI nākotni mazliet drošāku!